Four production tasks where reasoning regresses, plus a 5-question routing diagnostic.
8 min read
Just now
--
Press enter or click to view image in full size
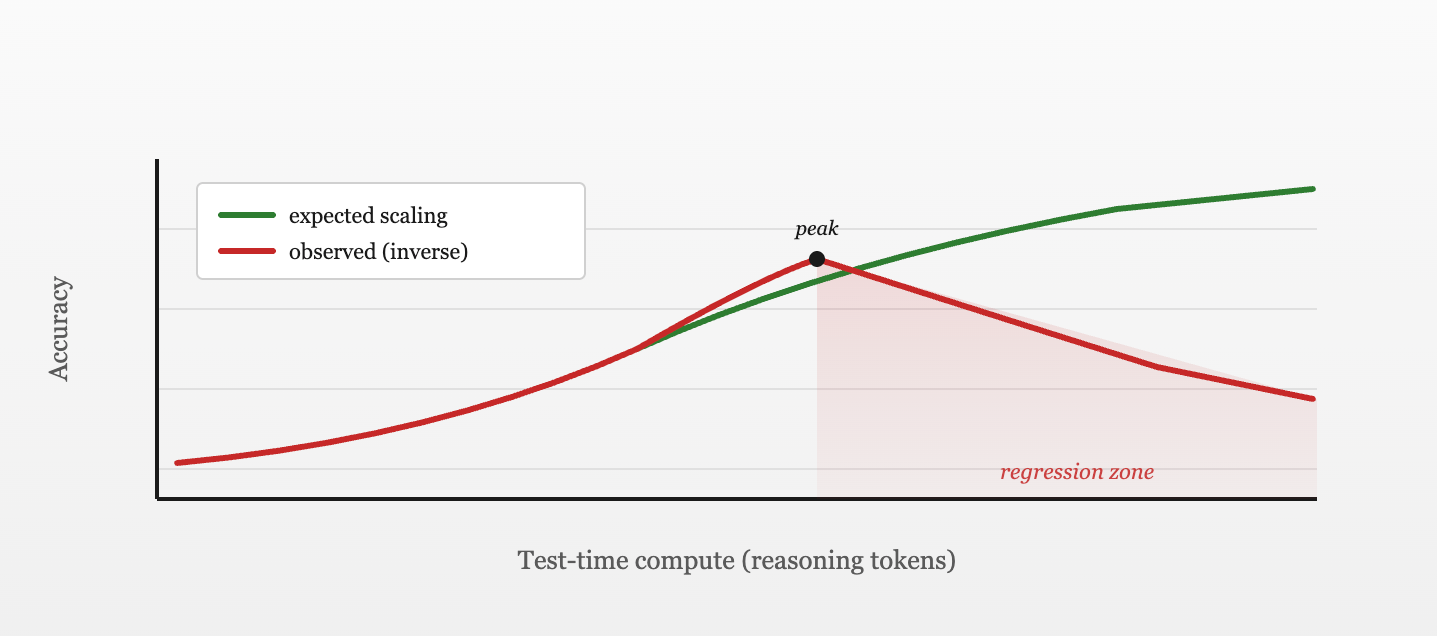
The benchmark says you should switch. Production says otherwise.
In a NeurIPS 2025 paper on chain-of-thought (CoT) prompting and instruction-following, researchers ran fourteen instruction-tuned language models against IFEval, a benchmark that scores whether the model obeys verifiable constraints in a prompt: things like “answer in exactly three sentences,” “do not use the letter e,” or “begin every paragraph with a different word.” They flipped on CoT prompting. Thirteen of the fourteen got worse. Llama3–8B-Instruct went from 75.2% accuracy to 59.0%, a 16-percentage-point regression caused by the model being asked to think out loud.
This finding sits awkwardly next to the dominant 2026 narrative. Trend reports, model-card press releases, and Q1 enterprise procurement decks all repeat the same claim: test-time compute is the new scaling axis, and switching from a chat model to a reasoning model like DeepSeek-R1 (R1), Qwen3, Kimi K2, or GPT-OSS-120B is a pure upgrade.
The benchmarks confirm this on the tasks the benchmarks measure. The benchmarks do not measure most of production.