7 min read
6 hours ago
--
Press enter or click to view image in full size
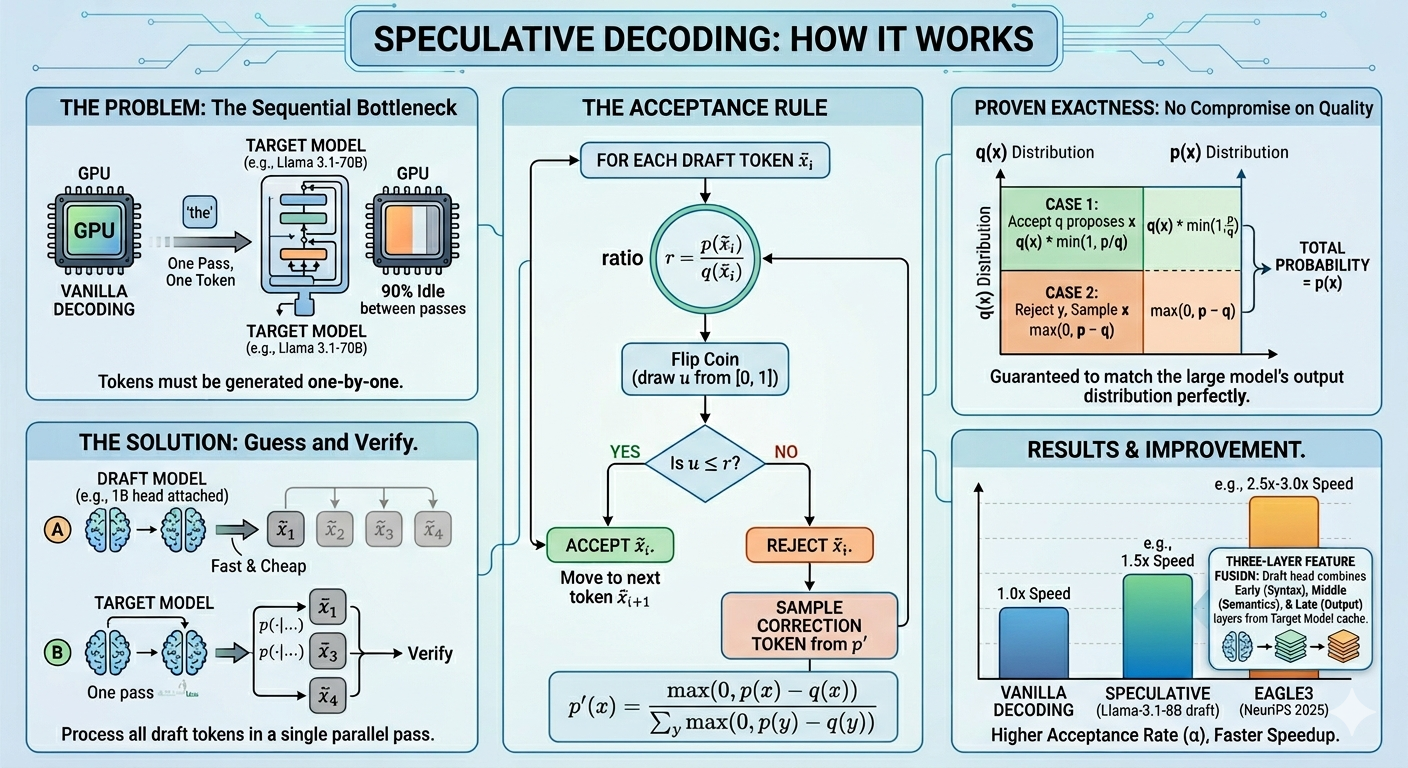
Every token your LLM generates costs one full forward pass. One pass, one token. No shortcuts.
That is the bottleneck. Not compute. Not memory bandwidth, exactly. The sequential dependency. Token N cannot be generated until token N−1 exists. The GPU sits 90% idle between passes, waiting.
Speculative decoding breaks this. It lets a small model guess several tokens ahead, then lets the big model verify all of them in a single pass.
That sentence sounds like it should change the output. It does not. The math guarantees it. That guarantee is what nobody shows you.
Let us examine it.
The setup
You have two models.
The target model p. This is the large model. Llama-3.1–70B, say. Slow. Expensive. Correct.
The draft model q. This is small. Maybe a 1B parameter head attached to the target model’s own internals. Fast. Cheaper. Slightly wrong.
You want outputs that look exactly like p generated them. You want to use q to go faster. These seem to be in conflict.
They are not.