A practical guide to categorization in credit scoring
22 min read
Just now
--
Press enter or click to view image in full size
What if your credit scoring model fails not because the algorithm is weak, but because the variables were not prepared in a way the model can properly understand?
In credit risk modeling, we often focus on model choice, performance metrics, feature selection, or validation. But before estimating any coefficient, another question deserves attention: how should each variable enter the model?
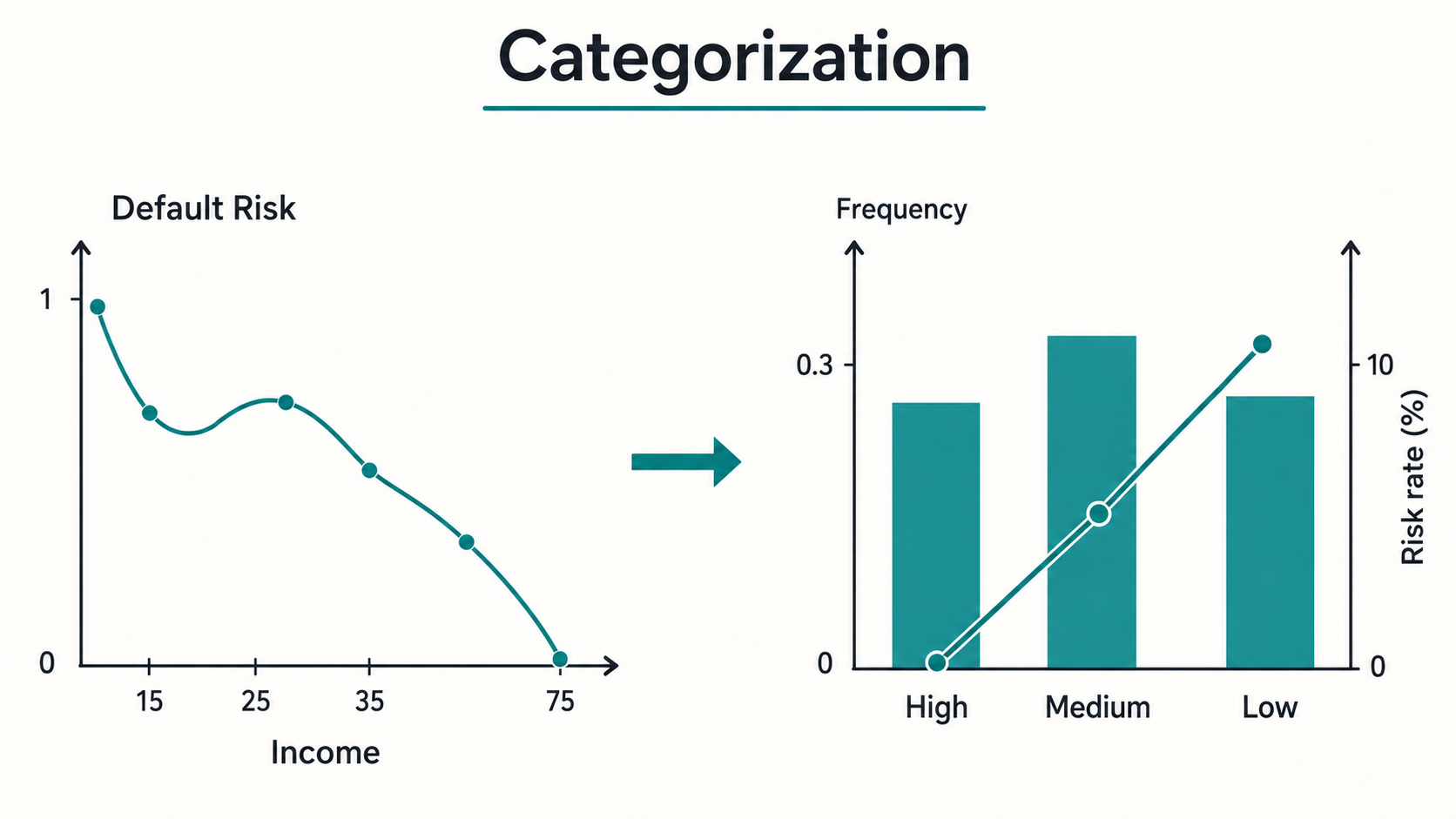
A raw variable is not always the best representation of risk.
A continuous variable may have a non-linear relationship with default. A categorical variable may contain too many modalities. Some variables may include outliers, missing values, unstable distributions, or categories with very few observations. If these issues are ignored, the model may become unstable, difficult to interpret, and less reliable in production.
This is where categorization becomes important.
Categorization, also called coarse classification, grouping, classing, or binning, consists of transforming raw variable values into a smaller number of meaningful groups. In credit scoring, these groups are not created only for convenience. They are created to make the relationship between the variable and default risk clearer…