11 min read
2 hours ago
--
I ran the same 18 prompts through three agents: Claude Code on Opus 4.7, OpenClaw on Sonnet 4.6, and Nous Research’s Hermes Agent — a project that didn’t exist 12 weeks ago and now serves more daily tokens on OpenRouter than any other open-source agent in the world.
Press enter or click to view image in full size
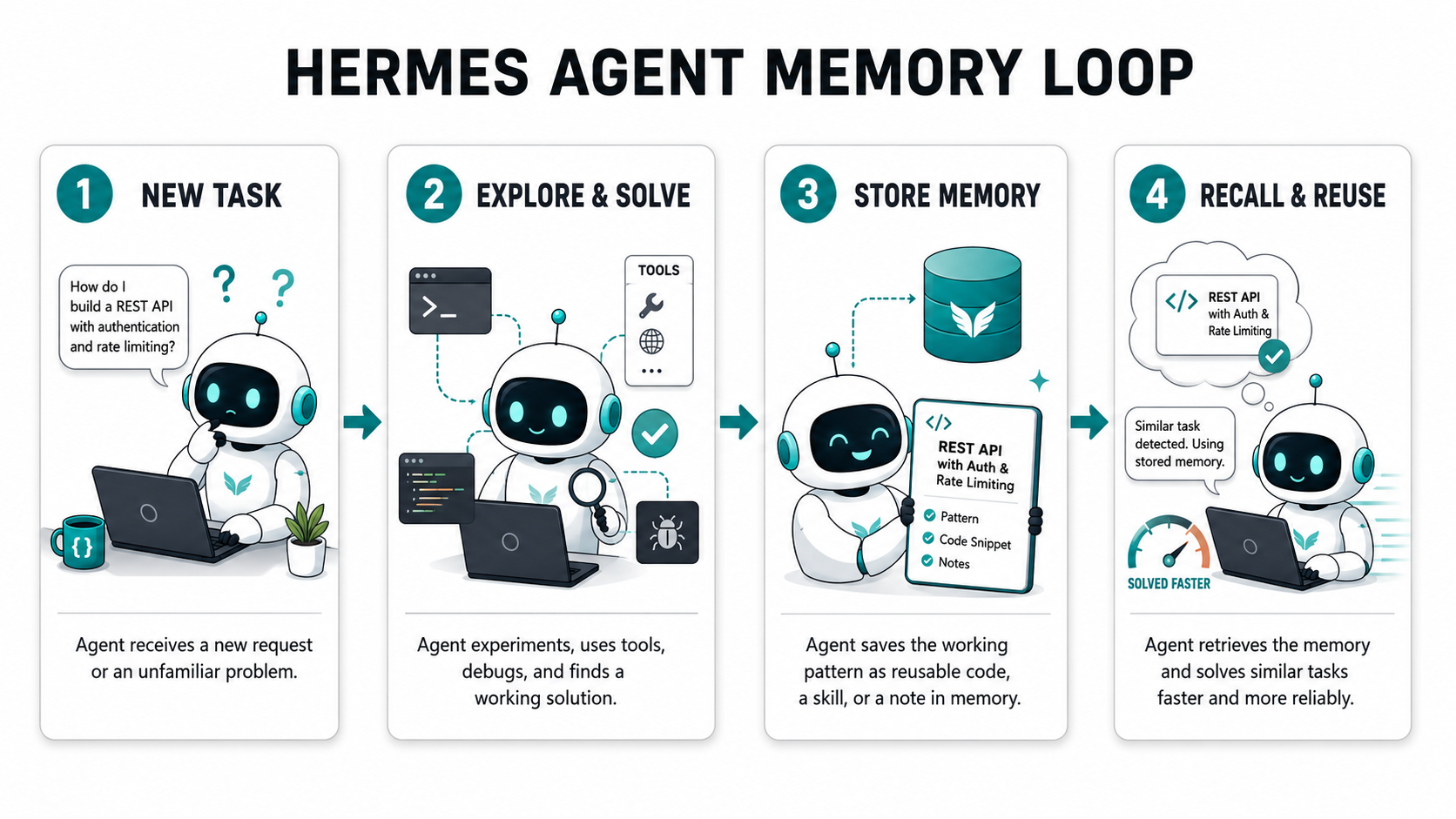
Hermes won 14 of 18. The four it lost, it lost to Claude Code on raw coding chops. The 14 it won, it won by doing something neither of the other two can do: it remembered last Tuesday.
That’s not a metaphor. Hermes ships with a SQLite database indexed by FTS5 that holds every session you’ve ever run through it. When you start a new chat at 9 AM on Monday and say “fix the bug we were chasing on Friday,” Hermes greps Friday’s transcript, pulls the relevant turns into context, and picks up where you left off. Claude Code and OpenClaw don’t. They start every session with an empty room.
I want to be careful here, because “self-improving” gets thrown around so loosely in AI marketing that it’s basically meaningless. So I’ll show the actual numbers, the actual failures, and the specific moment in each task where Hermes’ memory layer flipped the result.