Sub-agents, harnesses, and fleets. A new layer of tooling is forming above Cursor and Claude Code, and the engineers who find it first are operating at a different scale than everyone else.
9 min read
Just now
--
Press enter or click to view image in full size
The standard 2026 AI coding setup goes something like this. You open Cursor or Claude Code, you type a prompt, you wait, you review what the agent produced, you accept or reject, you move on. One developer, one agent, one task at a time. The pattern is familiar enough that it feels like the end state.
It isn’t.
A different layer of tooling has been forming above the agents themselves for about a year now, and most working engineers haven’t noticed it yet. Not because it’s hidden, but because it’s been growing in places the mainstream tech press doesn’t cover. GitHub repos with weird names. Discord communities for specific frameworks. Substack posts arguing about orchestration patterns. The category doesn’t have a clean name yet, but the tools are real and the adoption is genuine. Oh My OpenAgent has 39,400 stars. BMad-Method is in production at Fortune 500 engineering teams. Conductor, Multiclaude, Gas Town, Claude Squad. None of them are household names. All of them have working users.
What’s going on is that AI coding is splitting into layers. The model layer (Claude, GPT, Gemini) does the actual thinking. The agent layer (Cursor, Claude Code, Codex) wraps the model in a coding-aware interface. And now there’s a third layer forming above the agent layer, made up of tools that coordinate agents, manage their work, and let engineers run multiple agents in parallel without losing their minds.
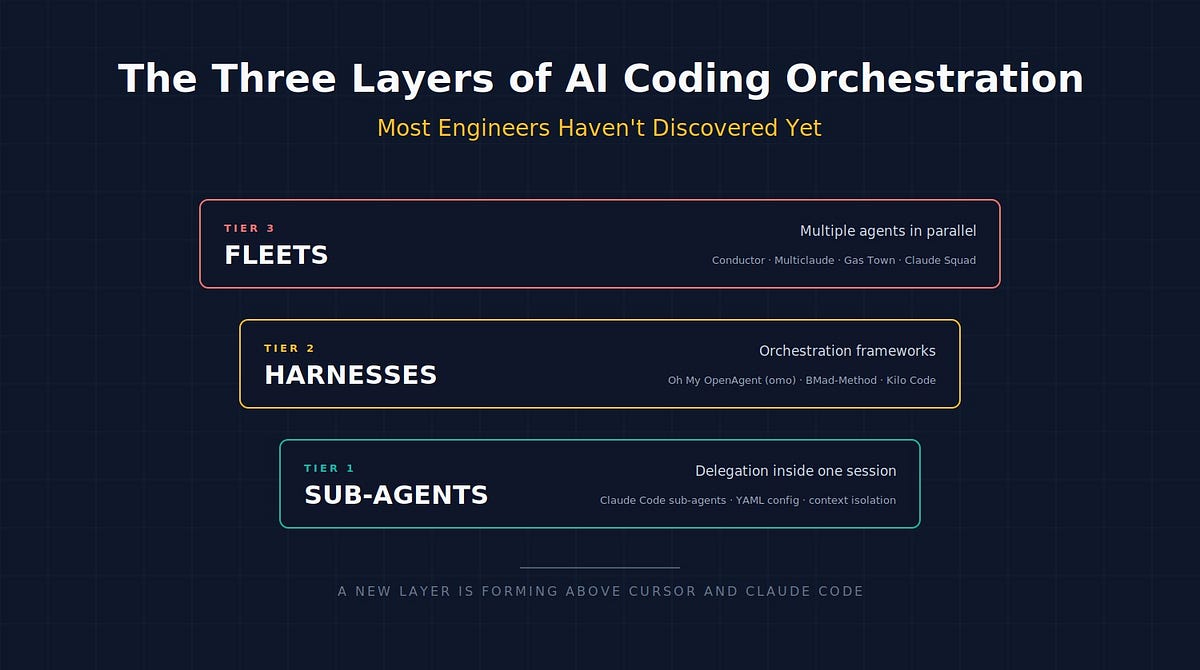
That third layer has three distinct tiers, each solving a different scaling problem. Most engineers are on Tier 0, using a single agent. The interesting work is happening at Tiers 1 through 3, and it’s worth understanding what’s there.
Tier 1: sub-agents inside a single session
The entry point. The thing you can adopt today without installing anything new.
Sub-agents are a feature inside Claude Code, and a similar pattern exists in Kilo Code, where the main agent can delegate focused tasks to isolated child sessions. Each child runs in its own context window with its own system prompt and tool permissions, does one specific job, and returns a summary. The parent never sees the child’s intermediate reasoning, file reads, or dead ends. Only the result.
The mechanics are straightforward. You define a sub-agent as a markdown file with YAML frontmatter in .claude/agents/. The frontmatter declares the agent's name, when to use it, which tools it can access, which model it runs on. The body is the system prompt. Claude Code can either invoke sub-agents automatically based on the task description, or you can call them explicitly with @agent-name.
The reason this matters more than it sounds: context window pollution is the silent killer of long AI coding sessions. Every file read, every tool output, every intermediate reasoning step accumulates in the parent context and you pay for it on every subsequent turn, both in cost and in degraded response quality. Sub-agents fix this by isolating the heavy work. A code-reviewer sub-agent reads ten files, thinks through them, returns a one-paragraph summary. The parent context stays clean.
Claude Code ships with three built-in sub-agents that illustrate the pattern. Explore is read-only and runs on Haiku for speed and cost, designed to search a codebase without making changes. Plan gathers context before Claude presents a strategy in plan mode. General-purpose handles tasks that need both exploration and modification. You rarely invoke these directly. The router handles it.
Where this tier breaks down: sub-agents work within a single session. They’re great for delegating focused tasks inside one workstream, but they can’t coordinate across independent workstreams, and they don’t help if you want to run three different features in parallel. For that, you move up a tier.
Tier 2: orchestration frameworks (the agent harnesses)
The middle tier is where things get interesting, and it’s where the most exciting open-source work has been happening this year.
The tools at this layer don’t replace your agent. They wrap a structured methodology around it. You’re still using Claude Code or OpenCode underneath, but instead of typing prompts directly into the agent, you’re working through a framework that decides which sub-task happens when, which specialized agent handles each part, and how the work gets verified.
Two tools dominate this tier right now, and they take meaningfully different approaches.
Oh My OpenAgent (omo, formerly oh-my-opencode) is the high-engagement option. 39,400 GitHub stars, over 1.2 million downloads, an active Discord community. It’s built on top of OpenCode and runs as a CLI harness with a three-part pipeline: Sisyphus orchestrates and maps the codebase, Prometheus does strategic planning without writing code, Atlas executes verified plans. The autonomy lever is a three-letter command, ulw for "ultrawork," which triggers auto-planning, deep research, parallel agents, and self-correction loops with no babysitting. The aesthetic is power-tool-for-power-users. Engineers who like configuring their dev environment love it.
BMad-Method is the structured-process option, and it’s more interesting for teams. BMAD stands for “Breakthrough Method for Agile AI-Driven Development.” Rather than a CLI, it’s a methodology delivered as a set of markdown agents (Analyst, Product Manager, Architect, Developer, QA) that each handle one phase of a software development workflow. Configured with YAML, model-agnostic, works with any AI IDE that supports custom system prompts. The framework is now in v6 alpha and the project is being used by solo developers and Fortune 500 engineering teams alike. It’s the option that maps cleanly onto how organizations already structure work.
There are smaller players too. Kilo Code is an open-source competitor with its own Orchestrator Mode for parallel sub-task execution. The Open Agent (different project, similar name) is a single-binary self-hostable personal AI assistant with RAG and agent loops. OpenAI’s own Agents SDK sits in this space too, though it’s library-flavored rather than methodology-flavored.
Get Yashraj Behera’s stories in your inbox
Join Medium for free to get updates from this writer.
Remember me for faster sign in
What unites this tier: every tool at this layer is trying to add structure and methodology to the otherwise free-form interaction between you and the agent. The goal isn’t more autonomy. It’s more reliability through scoped, named, repeatable patterns.
Tier 3: fleet orchestration (running multiple agents in parallel)
The highest tier is where most engineers haven’t been yet, and it’s where the real productivity multipliers live.
The problem this tier solves: a single Claude Code session works well for one feature. The moment you try to pick up multiple tickets at once, you hit blockers. Git version control issues from having two branches checked out. Context window depletion from running sub-agents inside a single session. The session model breaks down when you want five agents working on five different things at the same time.
Fleet orchestrators fix this by running multiple Claude Code sessions in parallel, each in its own isolated git worktree, coordinated through a dashboard or kanban interface. The naming convention here is genuinely unhinged (Gas Town, Multiclaude, Antfarm, Claude Squad, Vibe Kanban, Conductor) but the tools are real.
A few worth knowing by name. Conductor is the fastest way to start. It runs locally, spawns multiple agents in isolated worktrees, gives you a dashboard for diff review and merge control. Good for 3 to 10 agents on a known codebase. Multiclaude is the team-friendly option, with “singleplayer” mode for solo work and “multiplayer” mode where teammates can review code before it merges. The supervisor agent assigns tasks to subagents. Gas Town is more complex and better for solo devs running ambitious hobby projects in parallel. Claude Squad and Antigravity sit in similar territory.
And then there’s the cloud-VM version of this tier, which deserves its own mention. Claude Code Web, GitHub Copilot Coding Agent, Jules (Google), and Codex Web (OpenAI) all let you assign a task, close your laptop, and come back to a pull request. No terminal, no local setup, agents running in cloud VMs. This is the “drain the backlog overnight” pattern, and it’s becoming a real workflow for engineering teams with well-defined ticket queues.
The cost dynamics at this tier deserve a brief honest note. Running 5 to 20 Claude Code agents in parallel is not cheap, and idle Opus sessions still consume token quota. Teams that move to fleet orchestration tend to invest in cost telemetry pretty quickly. The CloudZero piece from earlier this month frames this as graduating from a purchasing question to a FinOps problem.
The tension nobody at the orchestration layer wants to address
Here’s the honest counter-narrative, because no piece on this category is complete without it.
There’s a real argument floating around right now that orchestration frameworks are scaffolding that frontier models will absorb. A recent Substack post titled “Are Agent Orchestration Frameworks Doomed in the Singularity Age?” makes the case bluntly: LangChain abstracted chains for unreliable models, LangGraph added graphs for state and routing, CrewAI introduced crews and managers, and all of them were brilliant solutions for their time. But frontier models in 2026 handle natively what required scaffolding a year ago. Persistent long-context sessions. Parallel server-side tool calls. Dynamic planning and self-correction loops. Clarification requests without breaking flow. The argument is that the orchestration layer, like the prompt engineering layer before it, will get absorbed into the models themselves within 18 months.
The counter-argument is that even if frontier models can do orchestration natively, the infrastructure of orchestration (worktree isolation, parallel session management, cost telemetry, human-in-the-loop review patterns) is independent of model capability and will remain useful regardless. Claude Code’s own sub-agents and Agent Teams feature support this read: Anthropic is building orchestration directly into the agent, which validates the pattern even as it potentially eats the standalone tools.
The honest answer is probably that both things are true. The high-level “frameworks for prompting models well” layer will get squeezed out as models get smarter. The low-level “infrastructure for managing many concurrent agents in production” layer will become standard kit. Where the line sits between those two is the bet every tool in this space is implicitly making, and we’ll know who got it right by 2027.
What to do with this
A short, practical takeaway, because it’s worth saying directly.
If you’re a solo developer using Claude Code or Cursor and you’ve never touched sub-agents, start there. It’s free, it ships with the tool, and the productivity gain from properly isolating context-heavy tasks is immediate. A weekend of reading the documentation and writing two or three custom sub-agents for your workflow will pay back faster than almost any other AI tool investment in 2026.
If you’re already comfortable with sub-agents and you find yourself wanting more structure around your agent workflows, that’s the signal to try Tier 2. Oh My OpenAgent if you like power tools and CLI workflows. BMad-Method if you work in a team or you want a framework that maps to how organizations already structure work.
If you’re running enough AI-assisted work that you regularly want three or four features happening at once, Tier 3 is where the real lift is. Start with Conductor for solo work, Multiclaude if you need team review patterns, the cloud-VM tools (Claude Code Web, Codex Web, Jules) for overnight backlog work.
The thing that ties all of this together is a shift in how engineers are interacting with AI coding tools. The 2024 pattern was conversation. You typed, the model responded, you reacted. The 2026 pattern is orchestration. You define what work needs doing, you set up the agents and the structure, and you check in on results. It’s less like chatting with an assistant and more like running a small team of contractors, each with a clear scope and a specific job.
Most engineers haven’t made that shift yet. The ones who have are operating at a different scale, and the gap is starting to compound. The orchestration layer doesn’t have a clean name yet, but the tools are real, the adoption is growing, and the engineers who get good at it now are going to have a meaningful advantage when the rest of the industry catches up in 2027.
The three layers are there. Most of the field is still on Tier 0. The opportunity is to move up.
If you’re running one of these orchestration patterns in production, drop a comment. The practical knowledge in this space is still mostly in Discord servers and GitHub issues, and pulling it into the open is overdue.