The continuous evaluation loop is the new CI/CD pipeline. Here’s what that means in practice.
13 min read
Just now
--
Press enter or click to view image in full size
AgentOps: DevOps in the Agentic Era
Press enter or click to view image in full size
The first time I deployed a non-trivial agent to a customer-facing environment, I did what any engineer with a decade of DevOps muscle memory would do. I wrote unit tests. Wired up a CI pipeline. Ran it through staging. Watched the green checks pile up. Shipped it.
Two days later, the agent decided to call the same tool seventeen times in a row before giving up. The tests had all passed. The logs were clean. The dashboards were green. And yet, in production, the thing was quietly losing its mind.
That’s the moment most teams realize the operational playbook we spent fifteen years perfecting for deterministic services doesn’t quite work anymore. The shape of the problem has changed. Our tooling hasn’t caught up. And the discipline emerging to fill that gap call it AgentOps, LLMOps, GenAIOps, whatever vocabulary survives the next hype cycle is genuinely different from what came before.
This piece is about what’s different, why it matters, and what a practical AgentOps stack actually looks like when you have to run one
The Amazon story, retold for agents
In 2001, Amazon was a monolith. One codebase, one deployment, hierarchical teams, and a development velocity that was getting worse every quarter. The fix now textbook was a re-architecture into microservices owned by small, autonomous “two-pizza” teams. It took years. It rewrote how the company shipped software. And it required a new operational discipline that we now just call DevOps.
There’s a useful parallel happening right now with agents.
For the last two years, most production agent systems have been monoliths in spirit. One giant prompt, one over-stuffed agent armed with twenty-plus tools, one team trying to debug why it keeps misrouting customer queries. Anyone who has lived inside a “mono-agent” knows the feeling: every new capability degrades an existing one, the prompt becomes an archaeological dig, and nobody is quite sure which change broke the eval or whether the eval was ever measuring the right thing.
The direction the field is moving is toward decomposed, specialized agents that talk to each other over open protocols like MCP, each owning a narrow domain, each independently testable and deployable. Multi-agent ecosystems. Hundreds of micro-agents. Small teams owning each one.
If that sounds like microservices déjà vu, it is. The architectural shift is recognizable. What’s not recognizable and what most teams underestimate is the operational discipline the new architecture demands.
What actually breaks
DevOps was built around a comfortable assumption: given the same inputs, your code produces the same outputs. Bugs are deterministic. Tests can be exhaustive. A green build means something.
Agents break all three.
Non-determinism is the default, not the exception. The same prompt with the same tools and the same input can produce two different trajectories on two different runs. Your test suite passing once tells you almost nothing about whether it will pass again.
Correctness is no longer binary. “The function returns 42” is verifiable. “The agent’s response is helpful” is not. You’re now in the business of measuring quality distributions, not pass/fail. And quality drifts silently as models update, as user behavior shifts, as your tool set grows.
Logs are the wrong primitive. A traditional log line tells you what happened. An agent failure is rarely about a single event; it’s about a sequence which tools were called, in what order, with what arguments, against what context, producing what intermediate reasoning. You need traces, not logs. Hierarchical, spans-within-spans, every LLM call, every tool call, every retrieval, every retry. Without that, debugging an agent is guesswork.
Tests get replaced by evals. Unit tests still matter for your code paths, but the thing that actually tells you whether the agent works is an evaluation suite running against representative inputs, scoring outputs along multiple dimensions, comparing versions over time. Evals are to agents what tests were to microservices: the load-bearing signal that lets you ship with confidence.
Take those four shifts together and you get the actual definition of AgentOps. It’s not “DevOps but with LLMs.” It’s the operational discipline of running systems whose correctness can only be observed statistically, debugged via traces, and improved through continuous evaluation.
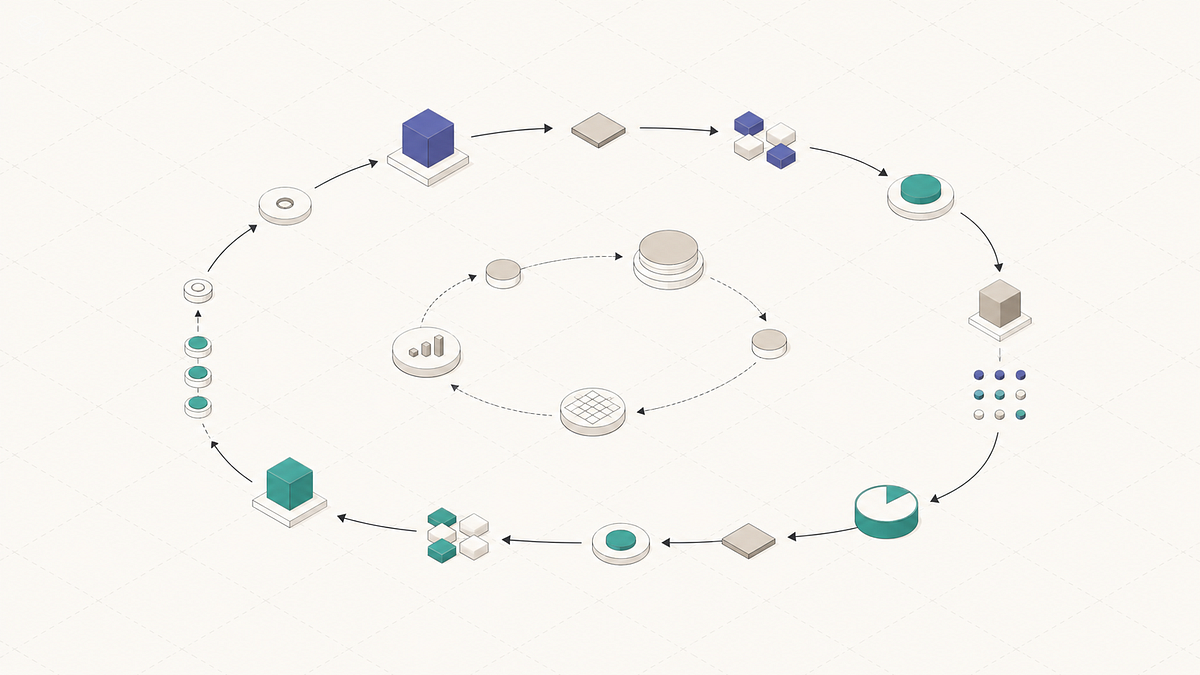
The continuous evaluation loop
Here’s the mental model that has held up best for me. Forget the org chart, forget the tooling for a second, and look at the loop:
You start with a dataset a collection of inputs that represent how your agent will actually be used. Happy paths, edge cases, the adversarial stuff that tends to break things. This is your golden set, and it’s the single most undervalued artifact in the entire stack. Most teams build it too late, and too small.
You run experiments against that dataset different models, different prompts, different tool configurations, different agent topologies and you evaluate the results. Some of those evaluators are rule-based (did it call the right tool? is the JSON valid?). Some are model-based (LLM-as-a-judge for relevance, faithfulness, toxicity). Some are human (a domain expert annotating outputs in a queue).
When something looks good enough, you ship it. In production, you trace every interaction full hierarchical traces, with inputs, outputs, latencies, costs, tool calls, the lot. You run online evaluators against those live traces to catch quality regressions in real time. And critically this is where most teams stop short the interesting production traces get pulled back into your dataset, annotated, and turned into new test cases for the next iteration.
That’s the loop. Dataset → experiment → evaluate → deploy → trace → annotate → back to dataset. Offline and online, feeding each other. The faster you can run that loop, the faster your agent improves. The cleaner your tooling, the faster the loop runs.
This is where a dedicated observability and evaluation platform earns its keep. I’ve been using Langfuse as the operational backbone for this loop, so let me explain what it actually does and why it matters.
Where Langfuse fits
Langfuse is an open-source LLM engineering platform that sits at the center of the continuous evaluation loop. It’s framework-agnostic it integrates with LangGraph, LangChain, CrewAI, LlamaIndex, the OpenAI Agents SDK, Strands, Semantic Kernel, Vercel AI SDK, and a long tail of others and at its core it speaks OpenTelemetry. That last part matters more than it sounds.
OTel-native means you’re not locked into a proprietary tracing protocol. The same OTLP exporter that feeds your application traces to your observability backend can fan out a copy to Langfuse. Your agent traces and your application traces live in the same semantic universe. You can self-host Langfuse, run it on the cloud version, or do both for different environments. The portability is real.
Here’s how it plugs into each stage of the loop:
Tracing. Every agent run produces a hierarchical trace: the user input at the top, then the LLM call, then the tool calls (with arguments and results), then the next LLM call, and so on, with token counts and costs and latencies on every span. When something goes wrong in production, you don’t reconstruct the failure from logs you open the trace and watch the agent’s reasoning unfold span by span. The first time you debug a misbehaving agent this way, you wonder how you ever did it the other way.
Prompt management. Prompts get versioned outside your code. You change one, you can roll it back without a deploy. You can A/B test prompt variants in production. This is one of those features that sounds boring on paper and becomes essential the moment your prompt count crosses about twenty.
Datasets. You build golden datasets directly in the platform, or by promoting interesting production traces into them. The dataset becomes the contract: any version of your agent has to perform well against it before it ships.
Experiments. Run a dataset through any combination of model / prompt / tool config and get a scored comparison. Did Claude 4.5 Sonnet beat GPT-5 on this task? Did the new prompt regress on edge cases while improving the happy path? You stop guessing and start measuring.
Evaluators. Rule-based, LLM-as-a-judge, or human-in-the-loop. Configure once, run offline against datasets or online against live production traces. The same evaluator can serve both modes.
Annotation queues. Domain experts review production traces, label them, and feed them back into the dataset. This is the bridge between “users are complaining about something” and “we have a test case that reproduces it.”
Nothing in that list is magic. What’s valuable is that all of it lives in one place, wired together, with a real UI and real APIs. You can absolutely stitch this together yourself out of OTel collectors, a vector store, a Postgres table for datasets, some Python scripts, and a Streamlit dashboard. Plenty of teams do. The question is whether that’s the wheel you want to be reinventing while your competitors are shipping agents.
Three environments, one loop
The continuous evaluation loop maps cleanly onto three environments, and I’d argue this is the single most important pattern to internalize when you’re setting up AgentOps for a team.
Experimentation and HPO (development). This is where engineers iterate fast change a prompt, swap a model, try a new tool, run it against the dataset, see what happens. Traces here are ephemeral; what matters is the experiment-to-experiment comparison. Hyperparameter optimization in the agent sense means sweeping over models, prompts, temperature, tool subsets, and seeing which combination wins on your evaluators. Langfuse Experiments give you the comparison view directly.
Get Sai Kumar Yava’s stories in your inbox
Join Medium for free to get updates from this writer.
Remember me for faster sign in
QA and testing in CI/CD. When you push a change, the pipeline runs a subset of your evaluators against your golden dataset locally not against a remote service, because you want CI to be fast and hermetic. Tool-call accuracy, factuality on a known set, regression checks against the previous version. If the evaluators pass, the agent is deployed to a test environment, possibly with ephemeral runtime instances per feature branch. The traces from these runs go to a tst project in Langfuse for inspection.
Production operations. The agent runs against real users. Every interaction produces a trace. Online evaluators run continuously toxicity, latency, cost, response relevance and dashboards aggregate them. When quality drops, you know within minutes, not weeks. Interesting traces (failed ones, low-rated ones, expensive ones) get pushed to an annotation queue. Domain experts label them. Labeled examples get added to the golden dataset. The next experiment cycle starts with a better benchmark than the last one.
The persistent state datasets, evaluator configs, annotations lives in one Langfuse instance and is shared across environments. The traces from each environment live in their own project, so dev noise doesn’t pollute production analysis. That separation is small in implementation effort and large in operational sanity.
The failure modes worth knowing
After enough agent deployments, you start to see the same failures recurring. They’re worth naming because they each have a different fix and a different evaluator pattern.
Underspecification. The agent works on the cases you tested and falls over on the cases you didn’t. The fix is dataset coverage. Pull production traces, find the categories you missed, add them. This is the single most common failure I see, and it’s also the most tractable you just need to actually do the work of expanding the dataset.
Generalization failure. The LLM behind the agent doesn’t generalize from its instructions the way you assumed it would. A prompt that works perfectly with one model fails subtly with another. Evals catch this specifically, running the same dataset across models and watching the score deltas.
Trajectory drift. The agent reaches the right final answer through the wrong path calling tools it shouldn’t, making redundant searches, taking five steps where one would do. End-to-end evaluators miss this entirely; trajectory evaluators (which score the sequence of tool calls against an expected set) catch it. This is the failure mode that costs you money, because trajectory drift shows up first on your token bill.
Single-step failures. Inside a long agent run, one step picks the wrong tool or constructs the wrong query, and everything downstream is corrupted. End-to-end evals can mask these because the agent sometimes recovers. Step-level evaluators on the specific span catch them directly.
The point isn’t to memorize the taxonomy. It’s to recognize that “the agent is broken” is never a useful description of what’s wrong, and your evaluator design should reflect the granularity of failure modes you actually care about.
What this actually changes for engineering culture
The technical shift is the easy part. The cultural shift is harder, and it’s where most teams stall.
DevOps demanded that developers care about operations that the people writing the code also owned the pager. AgentOps demands something further: that the people writing the agent also own the evaluation. You can’t outsource eval design to a QA team because evaluators are themselves a modeling problem. Picking the right LLM-as-a-judge prompt, choosing the right scoring rubric, deciding which failure modes matter these are engineering decisions, and they have to live with the team building the agent.
The two-pizza team for an agent looks something like: one or two engineers who own the agent code and prompts, a domain expert who owns annotation and dataset curation, and shared platform infrastructure (the Langfuse instance, the CI templates, the deployment runtime) provided by a central team. The domain expert is the role most organizations forget to staff. Without them, your evaluators are guesses about what good looks like. With them, your evaluators are grounded in the judgment of someone who actually knows.
The other cultural shift is comfort with statistical correctness. Engineers raised on deterministic systems hate this. “The agent passed 94% of the eval set” feels worse than “all tests pass.” It shouldn’t. The 94% is honest; the 100% green build was always a comforting fiction even for deterministic services, and it’s an outright lie for agents. The sooner the team makes peace with shipping against a quality distribution rather than a binary, the sooner the work gets easier.
So what should you actually do
If you’re standing up AgentOps from scratch, the order of operations matters. Here’s what I’d do, in order, knowing what I know now:
- Get tracing in before you do anything else. Wire your agent whatever framework you’re using to emit OTel traces, and point them at Langfuse. You’ll learn more about your agent in the first week of looking at real traces than in a month of reading prompts.
- Build a small, real dataset. Twenty examples is enough to start. Pull them from actual or anticipated usage, not from your imagination. Cover the happy path, two or three edge cases, one adversarial input.
- Write three evaluators. One rule-based (e.g., did it call the right tool?), one LLM-as-a-judge (e.g., is the response relevant?), one trajectory check (e.g., did it stay within an expected sequence). Resist the urge to write twelve. You’ll add more as you learn what actually matters.
- Hook evaluators into CI. Failing evals should fail the pipeline. This is the moment AgentOps becomes a discipline rather than an aspiration.
- Set up online evals in production. Even a single live evaluator say, response relevance gives you a quality signal that beats anything CloudWatch will tell you.
- Create an annotation queue. Have someone ideally a domain expert review fifteen minutes of traces a day. The dataset grows, the evaluators improve, the loop closes.
Notice what’s not on this list: picking the perfect framework, debating LangGraph versus CrewAI versus rolling your own, choosing the optimal model. Those decisions matter less than the loop. A mediocre agent inside a tight evaluation loop will outperform a sophisticated agent without one, every time.
The honest closing
I’m not going to pretend AgentOps is a solved discipline. It isn’t. The tooling is younger than the problem. The patterns are still being figured out in public. A lot of what passes for “best practice” today will look quaint in eighteen months.
But the direction of travel is clear. Agents are going from monoliths to ecosystems. Operations are going from logs to traces, from tests to evals, from binary correctness to quality distributions. And the teams that internalize the continuous evaluation loop dataset, experiment, evaluate, deploy, trace, annotate, repeat are shipping agents that actually work, while the teams still treating this like deterministic software are shipping agents that quietly lose their minds in production.
If you remember one thing from this piece, let it be that the loop is the unit of work. Pick tooling that makes the loop fast. Build culture that makes the loop honest. The rest follows.
If this resonated, you’ll probably get more out of going one level deeper. The Langfuse documentation is the most practical starting point I know of, and the open-source repo is genuinely readable if you want to understand how the platform works under the hood. Beyond that, the only real way to learn AgentOps is to ship an agent, watch it break, and close the loop.
References & further reading
The source talk this article builds on
- Tsakpinis, A. & Klingen, M. (2025). Continuous Evaluation, Monitoring, and Operations of AI Agents with AWS Bedrock AgentCore & Langfuse. Langfuse / AWS Deep Dive Days. https://www.youtube.com/watch?v=api-Z4TfDvM
- Companion slide deck: https://static.langfuse.com/events/2025_10_continuous_agent_evaluation_with_amazon_bedrock_agentcore_and_langfuse.pdf
Langfuse — the operational backbone
- Documentation: https://langfuse.com/docs
- LLM observability overview: https://langfuse.com/docs/observability/overview
- GitHub (open source): https://github.com/langfuse/langfuse
OpenTelemetry GenAI semantic conventions
- Spec overview: https://opentelemetry.io/docs/specs/semconv/gen-ai/
- Agent and framework spans: https://opentelemetry.io/docs/specs/semconv/gen-ai/gen-ai-agent-spans/
- GenAI client spans (inference, embeddings, retrieval, tool execution): https://opentelemetry.io/docs/specs/semconv/gen-ai/gen-ai-spans/
Model Context Protocol (MCP)
- Specification: https://modelcontextprotocol.io/specification/2025-11-25
- Anthropic’s introduction course: https://anthropic.skilljar.com/introduction-to-model-context-protocol
LLM-as-a-judge — the evaluation method underpinning model-based evals
- Li, H. et al. (2024). LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods. arXiv:2412.05579. https://arxiv.org/abs/2412.05579
- Gu, J. et al. (2024). A Survey on LLM-as-a-Judge. arXiv:2411.15594. https://arxiv.org/pdf/2411.15594
- Evidently AI’s practitioner guide: https://www.evidentlyai.com/llm-guide